
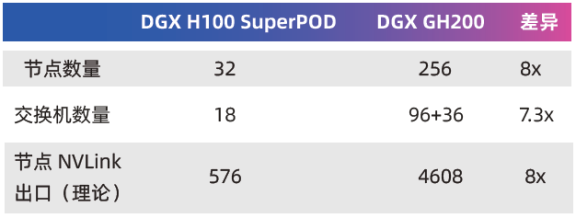
在 2023 年 5 月底召开的 COMPUTEX 上,英伟达(NVIDIA)公布了 256 个 Grace Hopper 超级芯片组成的集群,GPU 内存总量达 144TB。以 GPT 为代表的大语言模型(Large Language Model,LLM)对显存的容量需求极其迫切,巨量显存将迎合大模型的发展趋势。那么,这个前所未见的容量是如何达成的?
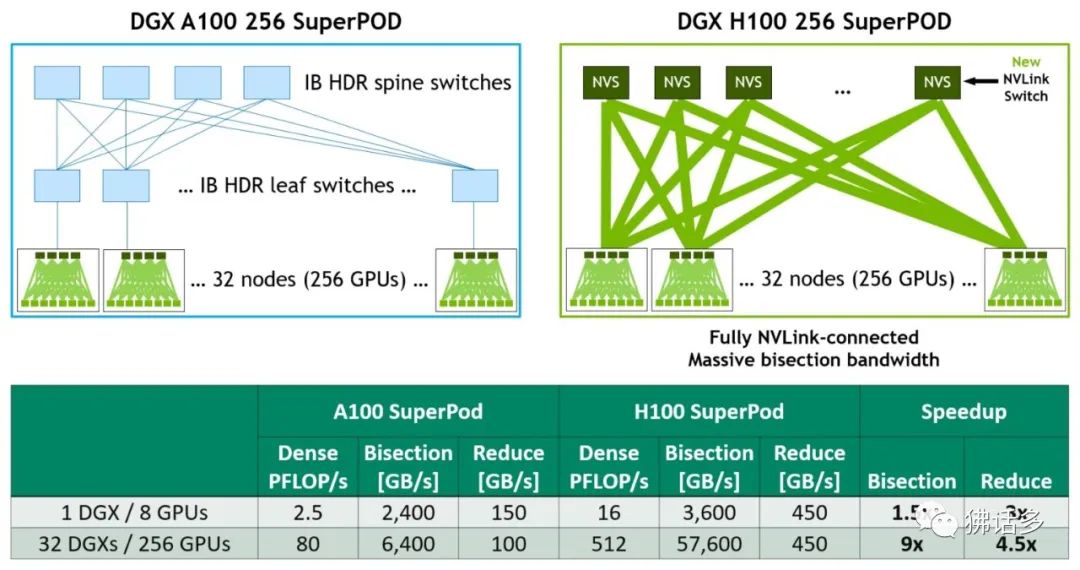
△ DGX A100 和 DGX H100 256 SuperPOD 架构
NVLink4 Network 是一个重大创新,让 NVLink 可以扩展到节点之外。通过 DGX A100 和 DGX H100 各自构建 256-GPU SuperPOD 的架构图,可以直观感受到 NVLink4 Networks 的特点。在 DGX A100 SuperPOD 中,每个 DGX 节点的 8-GPU 是通过 NVLink3 互联的,而 32 个节点则需要通过 HDR InfiniBand 200G 网卡和 Quantum QM8790 交换机互联。在 DGX H100 SuperPOD 中,节点内部是 NVLink4 互联 8-GPU,节点之间通过 NVLink4 Network 互联,各节点接入称为 NVLink Switch 的设备。
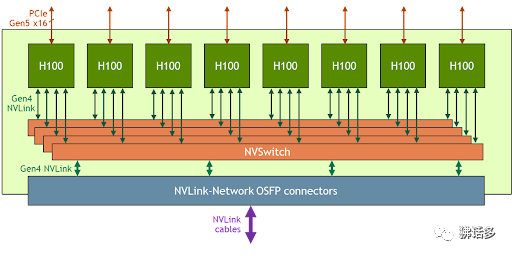
△ HGX H100 8-GPU 的 NVLink-Network 连接
在 NVIDIA 提供的架构信息中,NVLink Network 支持了 OSFP(Octal Small Form Factor Pluggable)光口。这也符合 NVIDIA 宣称的线缆长度从 5 米增加至 20 米的说法。DGX H100 SuperPOD 使用的 NVLink Switch 规格为:端口数量 128 个,32 个 OSFP 笼(cage),总带宽 6.4TB/s。
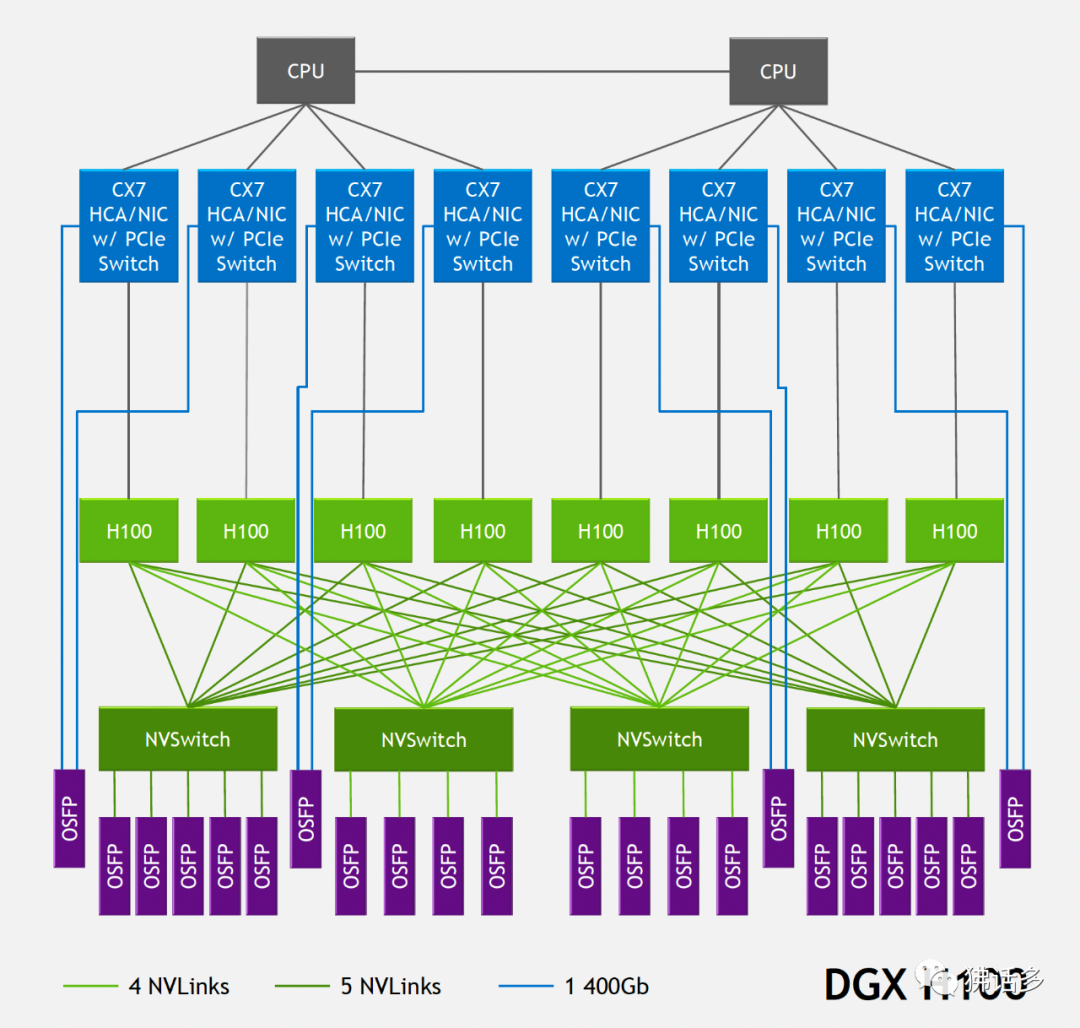
△ DGX H100 SuperPOD 节点内部的网络架构
每个 8-GPU 节点内部有 4 个 NVSwitch,对于 DGX H100 SuperPOD,每个 NVSwitch 都通过 4 或 5 条 NVLink 对外连接。每条 NVLink 是 50GB/s 带宽,对应一个 OSFP 则相当于 400Gb/s,是非常成熟的。每个节点总共需要连接 18 个 OSFP 接口,32 个节点共需要 576 个连接,对应 18 台 NVLink Switch。
DGX H100 也可以(仅)通过 InfiniBand 互联,参考 DGX H100 BasePOD 的配置,其中的 DGX H100 系统配置了 8 个 H100、双路 56 核第四代英特尔至强可扩展处理器、2TB DDR5 内存,搭配了 4 块 ConnectX-7 网卡——其中 3 块双端口卡为管理和存储服务,还有一块 4 OSFP 口的用于计算网络。
回到 Grace Hooper 超级芯片,NVIDIA 提供了一个简化的示意图,其中的 Hooper GPU 上的 18 条 NVLink4 与 NVLink Switch 相连。NVLink Switch 连接了“两组” Grace Hopper 超级芯片。任何 GPU 都可以通过 NVLink-C2C 和 NVLink Switch 访问网络内其他 CPU、GPU 的内存。
NVLink4 Networks 的规模是 256 个 GPU——注意, 是 GPU, 而不是超级芯片,因为 NVLink4 连接是通过 H100 GPU 提供的。对于 Grace Hopper 超级芯片,这个集群的内存上限就是:(480GB 内存 + 96GB 显存)× 256 节点 = 147456 GB,即 144 TB的规模。假如 NVIDIA 推出了 GTC2022 中提到的 Grace + 2 Hopper,那么,按照 NVLink Switch 的接入能力,那就是 128 个 Grace 和 256 个 Hopper,整个集群的内存容量将下降至约 80 TB 量级。

△ Grace Hooper 超级芯片之间的互联
在 COMPUTEX 2023 期间,NVIDIA 宣布 Grace Hopper 超级芯片已经量产,并发布了基于此的 DGX GH200 超级计算机。NVIDIA DGX GH200 使用了 256 组 Grace Hopper 超级芯片,以及 NVLink 互联,整个集群提供高达 144TB 的可共享的“显存”,以满足超大模型的需求。
先列几个数字来感受一下,NVIDIA 以一己之力打造的E级超算系统。
算力:1 Exa Flops (FP8)
光纤总长度:150 英里
风扇数量:2112 个 (60mm)
风量:7 万立方英尺/分钟 (CFM)
重量:4 万磅
显存:144 TB
NVLink带宽:230 TB/s
从150英里的光纤长度,我们就可以感受其网络复杂度。这个集群的整体网络资源如下:

由于 Grace Hopper 芯片上只有 CPU 和 GPU 各一,GPU 数量远少于 DGX H100,同样达到 256 个 GPU 所需的节点数大为增加,导致 NVLink Network 的架构复杂很多:
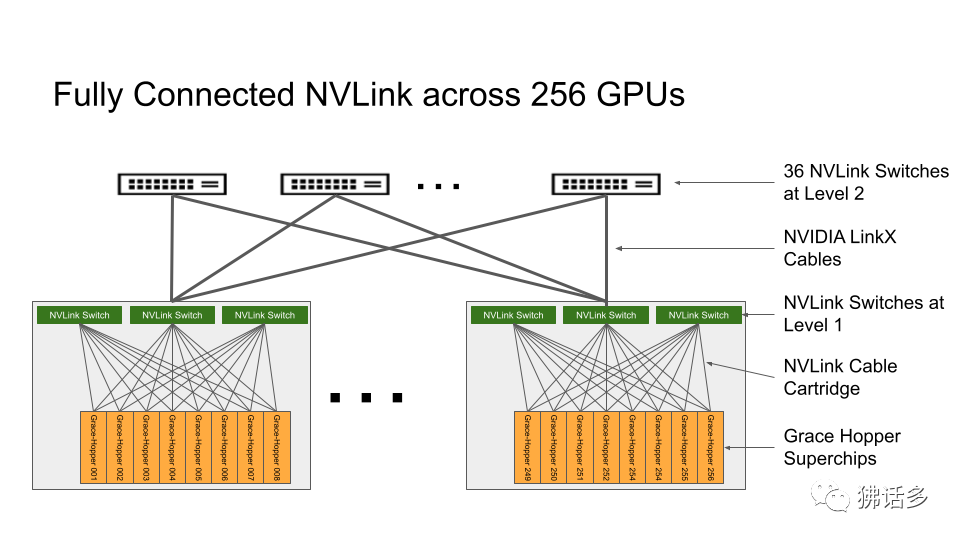
GH200 的每个节点有 3 组 NVLink 对外连接,每个 NVLink Switch 连接 8 个节点。256 个节点总共分为 32 组,每组 8 个节点搭配 3 台 L1 NVLink Switch,共需要使用 96 台交换机。这 32 组网络还要通过 36 台 L2 NVLink Switch 组织在一起。
相比 DGX H100 SuperPOD,GH200 的节点数量大幅增加,NVLink Network 的复杂度明显提高了。二者的对比如下:


{kind=link}
{kind=link}
{kind=link}
{kind=link}